

Speaking in Code: Why Website Construction Matters for SEO, Part 1


This is the first article in a three-part series on the importance of website construction for proper search engine optimization (SEO). The subsequent parts will be published biweekly.
Content is not king. It never was. We merely say it as a comfort to make sense of the sphinxlike, actual king: Meaning.
Meaning is the notion the writer intends to communicate. It must be clear, or it may go unnoticed. Content is merely the code used to express meaning. In this sense, content signifies something entirely different when an audience is not human, but rather, an algorithm.
In online marketing, human language exists as code in a similar fashion to HTML or JavaScript. It is essential to express meaning to both human and electronic audiences alike. And the process of SEO translates the very human search for meaning into a language that something alien can understand.
We all search for meaning, even the algorithms seeking to sort and categorize all possible answers to human questions. Appealing to these digital gatekeepers is why the way one constructs a website matters so much for Search optimization. We must express our meaning through types of content that algorithms can understand so that they will open the path for our human audience to reach us.
Meaning Is Everything
The successful conveyance of meaning is the true art of SEO. We seek to communicate meaning to familiar (human) and foreign (computer) entities simultaneously. We attempt to construct singular assets that express our intentions unambiguously and swiftly.
But how do you simultaneously express meaning to two completely different types of entities? To do this we must provide context for both human eyes and machine algorithms. And both assess context and meaning through different lenses.
The Mechanics of Meaning
This need for a two-pronged expression of topical meaning is why a website’s construction matters so much to SEO efforts.
While a human may read and click along from one webpage through to the next in a disposable single-use journey, the Search algorithm is mapping every piece of content on the Web as it goes, in order to understand what each piece can tell it about previous and future pieces it comes across. The algorithm seeks to understand human intentions not through one functional journey (like an individual query), but by viewing the relationships between every asset on the internet all at once.
For instance, a human may navigate to Google and input one query on where to find “bakeries near me.” They will ultimately land on one of the listed results, and that will be the end of the journey. The algorithm, on the other side, handles the heavy lifting. To serve the results that lead to the user’s selection, it must first index a few million pages, parse them, and distill them down to an ordered list categorized by personal relevancy to the user. It catalogs everything in order to understand and fulfill the query, because it uses code rather than a human brain to interpret meaning. That’s a lot of work to just to determine the most convenient place to grab a blueberry muffin!
Search engines are mechanical intermediaries between a human question and the full array of possible answers on the internet. And they don’t perceive the virtual world as we do. We must build Web content in a context that Search engines understand in order have then serve up the right content to our human audience.
SEO is the practice of being a bilingual builder, expressing our meaning through the context of the gatekeeper to reach our true audience. We optimize by reducing misunderstanding along this chain.
Viewing the Web through Robotic Eyes
How we construct a website matters to both Search bots and humans alike. And we need to appeal to both so that the bots disseminate our assets to the humans most likely to take our desired action. We must build bilingually, crafting everything in the languages of both the gatekeeper and the target.
Assuming we know how to write for other humans, let’s discuss in specifics how a Search spider understands and evaluates online assets. A search algorithm is visually impaired, scans each asset it comes across, and catalogs by relationship to create a larger semantic picture. This tells us a great deal about how to appeal to their sensibilities.
Parsing Context through URL Structure
No matter the page a Search spider enters a website through, it understands via URL construction that an interior webpage falls under the umbrella of its sub-directory, directory, and domain. The Search spider, therefore, sees the homepage as the most likely indicator of the property’s overall meaning (or at least its stated intention).
Directories create the first level of more specific branches outward from the homepage to deeper examinations of the main topic. Sub-directories branch out even further from there into more deliberate sub-topics. This hierarchical pattern continues with each deeper layer, much like a family tree, and terminates at the webpage level. The webpage itself provides the most specific information about an individual concept. A proper hierarchical structure is our first opportunity to convey meaning to Search engines, since Search engines contextualize all things top-down.
Example: Scribd URLs Show Proper Hierarchical Organization
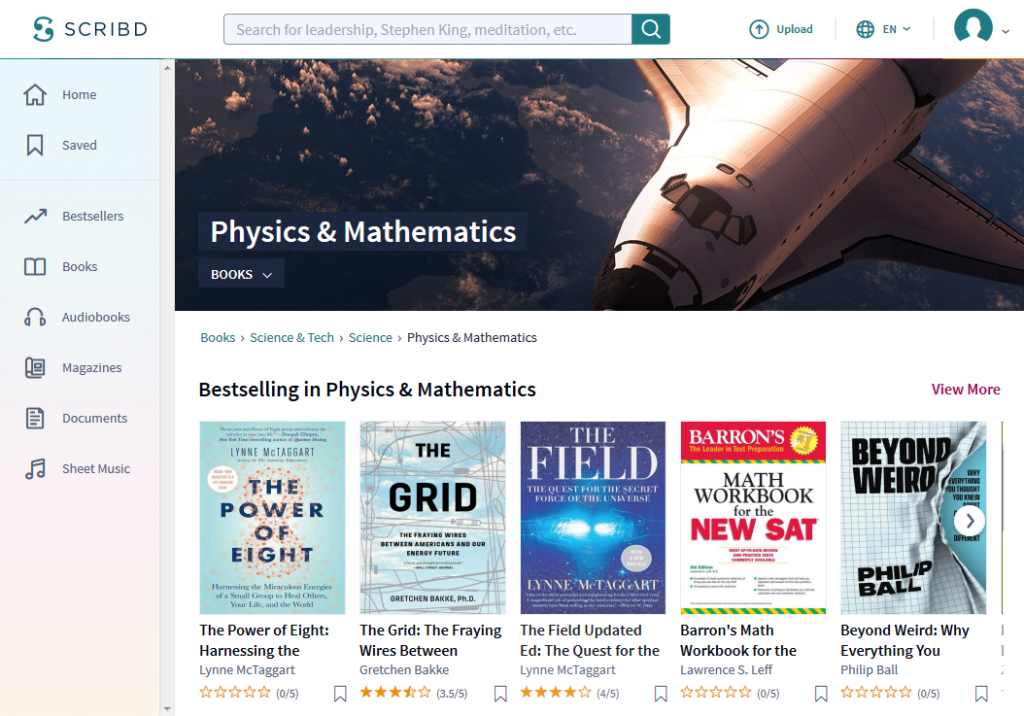
For example, the digital library subscription service Scribd organizes the inventory of its online repository with clear URL hierarchy. From the URL for its Physics & Mathematics books — https://www.scribd.com/books/Science-Tech/Science/Physics-Mathematics — a Search spider can gather quite a bit of information.
The spider can grab the website name (‘scribd’), the overall topic (‘/books/’), the category of the topic (‘Science-Tech’), the sub-category (‘Science’), and the role that the webpage plays in the website’s ecosystem (landing page for Physics and Mathematics books). This context is then passed to all of the books that fall within this inventory classification through internal linking and tagging.
Keep reading. This article continues in Part 2.
