






This is the second article in a three-part series on the importance of website construction for proper search engine optimization (SEO). Read Part 1 before continuing on, or just jump right in if you’re a fan of being confused.
The Broad Homepage & Specific Article
The Homepage is extremely potent because of top-down semantics. It is a Search spider’s starting point in understanding a website’s meaning.
The top-down sightline is also why articles perform so well in long-tail SERPs. By nature, they convey the specific meaning of one concept that is normally identified by its headline (this is also why search engines sometimes struggle to categorize and serve up headlines written in flowery prose in the SERPs, much to the dismay of traditional print writers).
To optimize for the Search spider’s top-down expectation of context, we define our core topic broadly on the homepage (among its UX needs important to the human audience), and add increasing specificity each level down. We must strive to express one core idea per level/page and organize our content from broad to specific.
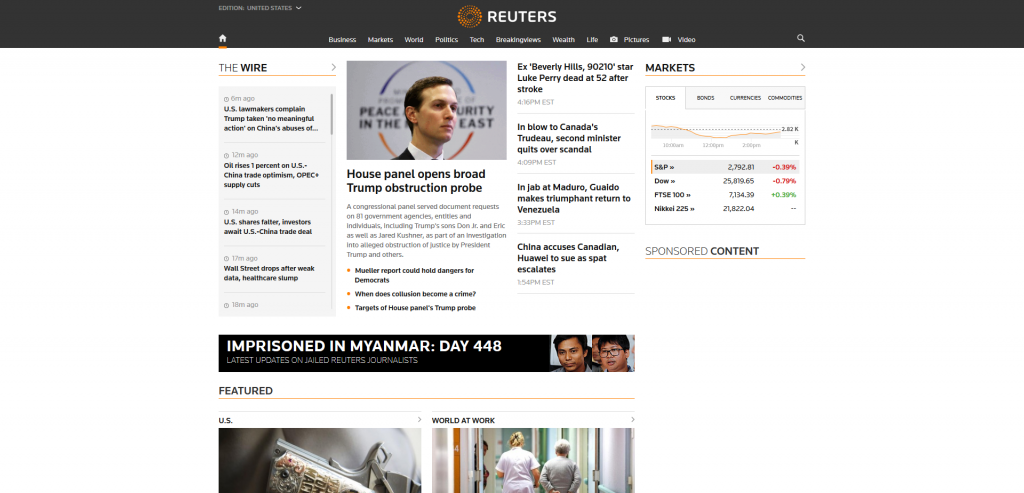
Example: Reuters Tells You It’s a News Provider
Through this approach, the homepage can provide broad context while an article supplies specific information, allowing the Search engine to sort accordingly.
For example, the homepage of Reuters (as of early March at least) consists mainly of navigations and an ever-changing array of timely articles; but it has two core pieces of static content that provide overarching context. Character limits aside, Reuter’s Title tag labels it “Business & Financial News, U.S & International Breaking News | Reuters.” Below the dynamic blocks of article lists, the homepage’s first and only piece of non-navigational body copy reads:
“Reuters, the news and media division of Thomson Reuters, is the world’s largest international multimedia news provider reaching more than one billion people every day. Reuters provides trusted business, financial, national, and international news to professionals via Thomson Reuters desktops, the world’s media organizations, and directly to consumers at Reuters.com and via Reuters TV. Learn more about Thomson Reuters products.”
Through that one short block of copy, a Search spider can grasp that Reuters should be parsed as a news website. It even uses the word ‘news’ three times within 60 words (5 percent of the static copy). That’s really useful information when Google has its own News vertical for Search. It helps prevent misunderstandings in which Reuters could be parsed as a provider of, say, scholarly papers. Now, a timely article like “Volkswagen signs e-vehicle startup as first partner for production platform” has a strong shot of appearing in Google News close to the time of its publication.
I’m purposely oversimplifying and viewing content parsing in a vacuum here, but I think the point is clear: tell Google what your site is. You’d be surprised home many websites overlook something so basic.
Keep reading. This article continues in Part 3.




